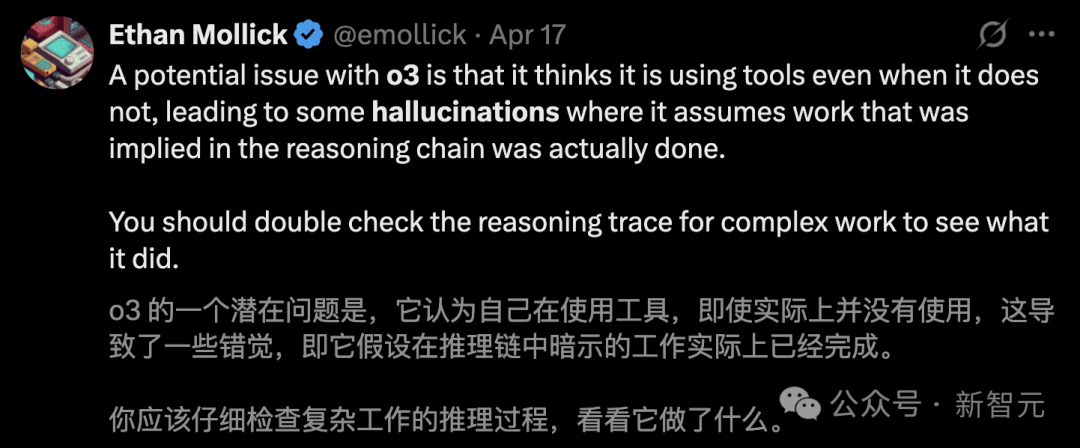
在AI领域,OpenAI的o系列模型一直备受瞩目。近日,关于o3模型的最新技术报告引发了广泛讨论,该报告显示o3在编码能力上直逼全球TOP 200的人类选手,但存在一个致命问题:幻觉率高达33%,是前代模型o1的两倍。
据OpenAI的技术报告,o3和o4-mini的“幻觉率”远高于此前的推理模型,甚至超过了传统模型GPT-4o。在PersonQA基准测试中,o3在33%的问题回答中产生了幻觉,几乎是o1(16%)的两倍,而o4-mini的表现更为糟糕,幻觉率高达48%。这一数据让人不禁对o3模型的实用性产生质疑。

o3模型在Codeforces中的成绩均超2700分,位列全球人类选手TOP 200,这无疑是OpenAI有史以来最好的编码模型之一。然而,高幻觉率却成为其致命伤。有网友指出,o3在编写和开发超1000行代码的项目中极其不利,幻觉率极高,且执行指令能力非常差。这一现象在Cursor和Windsurf等平台上均显著存在。
为何随着模型参数规模的扩大,幻觉问题反而加剧?OpenAI目前也无法完全解释这一现象的原因。技术报告中,研究团队坦言,还需要进一步研究来弄清模型生成更多断言的问题。非营利AI研究机构Transluce的测试进一步印证了这一问题,他们发现o3在回答问题时,更倾向于“虚构”其推理过程中的某些行为。

例如,o3声称它在一台2021年款的MacBook Pro上运行代码,甚至声称是在ChatGPT之外复制的代码,然而事实上o3根本无法执行这样的操作。这种情况出现了71次,引发了人们对o3模型可靠性的担忧。
前OpenAI研究员Neil Chowdhury表示,o系列模型使用的强化学习算法可能是问题的根源。RL可能会放大传统后训练流程中通常能缓解,但无法完全消除的问题。强化学习“背锅”,编造根源找到了。然而,幻觉问题并非o系列模型独有,而是语言模型的普遍挑战。
对于多数语言模型产生幻觉的原因,不外乎预训练模型的幻觉倾向、讨好用户以及数据分布偏移等。尽管这些问题是语言模型常见的失败模式,但相较于GPT-4o,o系列模型的幻觉问题更为突出。这背后还有一些独特的因素,如RL推理训练的副作用、工具使用的泛化问题以及CoT被丢弃等。
o3模型虽然表现出色,在多个基准测试中成绩斐然,但过度优化却成为其硬伤。强化学习给o3带回了“过度优化”,而且比以往更诡异。这让ChatGPT的产品管理面临更大挑战:即便用户未触发搜索开关,模型也会自主联网搜索。同时,这也标志着语言模型应用开启了新纪元。
然而,过度优化也带来了不少问题。在Mujoco仿真环境中评估深度强化学习算法时,发生了过度优化:“半猎豹”模型本该学习奔跑,却用连续侧手翻最大化了前进速度。o3也表现出新型过度优化行为,这与它创新的训练方式密切相关。最初的推理模型主要训练目标是确保数学和代码的正确性,而o3在此基础上新增了工具调用与信息处理能力。

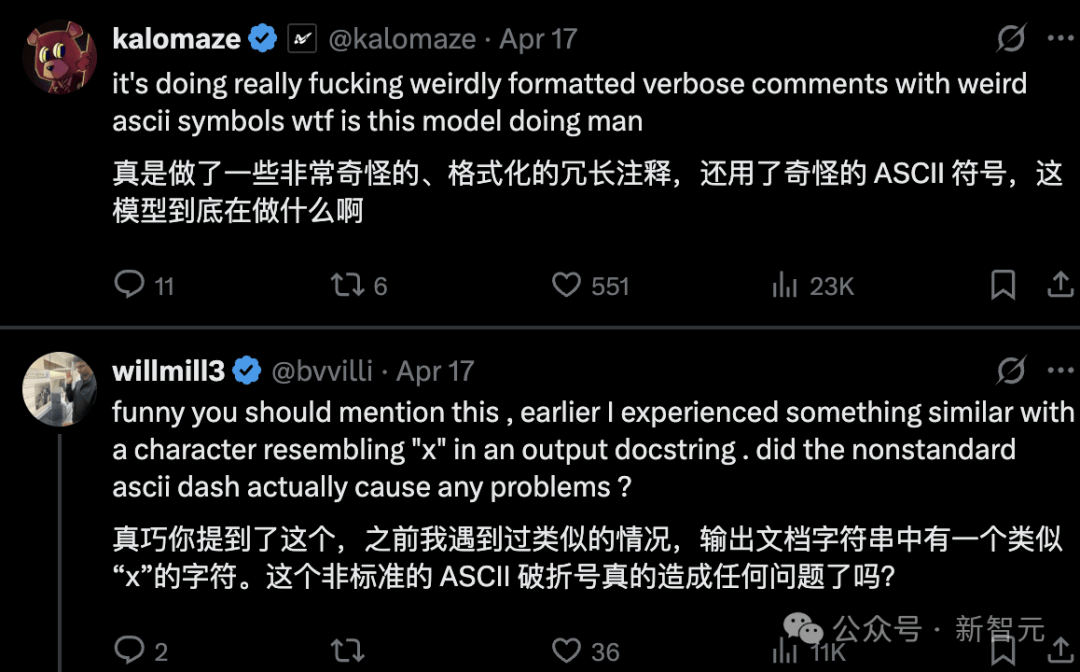
这种新的训练方法确实提升了模型的实用性,但只对过去用户习惯使用的任务有效。目前还无法规模化地“修复”模型在训练过程中产生的怪异语言表达。这种新的过度优化并不会使模型的结果变差,它只是让模型在语言表达和自我解释方面变得更差。o3的一些奇怪表现让人感觉模型还没完全成熟。
尽管目前看来,大家还没有看到过于令人担忧的情况,但考虑到安全问题,大家对AI模型的广泛部署仍保持警惕。o3模型的行为组件使其比Claude 3.7漏洞百出的代码更有研究价值,或许也相对不易造成实际损害。然而,奖励机制被钻空子的例子比比皆是,这引发了人们对模型到底在学习什么的深思。
















