近日,科技界掀起了一场关于meta最新推出的开源大模型Llama 4的风暴。4月5日,这家美国科技巨头宣布,其新一代大模型Llama 4已面世,包含Scout和Maverick两个基于混合专家(MoE)架构的版本,而更为强大的Llama 4 Behemoth仍在训练中。
meta官方宣称,Llama 4在多项基准测试中表现卓越,尤其是Llama 4 Behemoth,其在多个测试中的成绩超越了GPT-4.5、Claude Sonnet 3.7和Gemini 2.0 Pro等行业顶尖封闭模型。meta声称,Llama 4家族使用了混合专家架构,原生支持多模态,堪称“全能选手”。
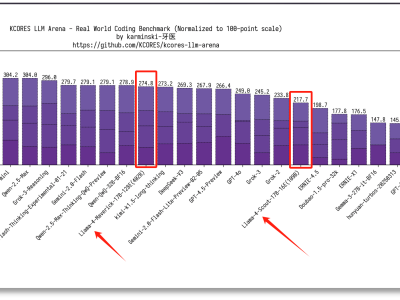
然而,就在Llama 4发布后不久,质疑声如潮水般涌来。开发者们实测后发现,Llama 4的实际效果远不如宣传中那般惊艳,甚至问题频出。特别是在编程等特定任务上,Llama 4的表现并不理想。Menlo Ventures的风险投资人迪迪·达斯直言,Llama 4实际上是一个糟糕的编程模型。

不仅如此,开发者们还质疑meta存在作弊“刷榜”的行为。他们指出,meta在大模型竞技场上使用的并非供开发者使用的Llama 4版本,而是针对人类偏好进行优化的定制模型。大模型竞技场官方也证实了这一点,并要求meta对此事作出澄清。
知名科技媒体TechCrunch也发表文章,指出meta新AI模型的性能测试“具有一定误导性”。文章认为,meta针对基准测试优化特定版本去打榜,却给开发者提供“基础版”的做法,让开发者难以依据榜单排名准确预估模型在实际应用场景中的真实表现。
面对外界的质疑,meta生成式AI副总裁艾哈迈德·阿尔·达赫勒在社交平台X上公开回应,坚称相关说法毫无事实依据。他解释称,部分用户在使用Llama 4模型时遭遇了质量不稳定问题,这是由于模型发布后仍在调整阶段,预计需要几天的时间来完善所有公开版本。

meta首席AI科学家、图灵奖得主Yann LeCun也转发了达赫勒的帖子,为Llama 4声援。然而,这场风波并未因此平息。一则自称由meta内部员工发布的爆料帖子,再次将meta推上了风口浪尖。该员工爆料称,Llama 4模型训练测试集作弊,自己已因此辞职。
爆料员工透露,尽管团队反复努力训练,Llama 4的内部模型性能始终无法达到开源SOTA基准,且差距明显。为达成目标,公司领导层提出在训练后期将各种基准测试的测试集数据混入训练或微调数据中。这一说法引发了广泛关注和讨论。

不过,由于爆料人并未实名,该帖子的真实性尚无法核实。meta的多位内部员工也在评论区实名进行辟谣,称团队绝不存在针对测试集过拟合训练的情况。这场关于Llama 4的争议,仍在持续发酵中。