在科技界的一次意外转折中,meta公司最新推出的AI模型系列Llama 4遭遇了用户反馈与官方宣传之间的显著落差。
上周六,meta自豪地宣布了Llama 4系列,包括Llama 4 Scout、Llama 4 Maverick和顶级版本Llama 4 Behemoth。官方宣传中,这些模型在大型语言模型领域展现出了不俗的实力,特别是Llama 4 Maverick,在多项任务中名列前茅,甚至超越了DeepSeek等其他知名模型。
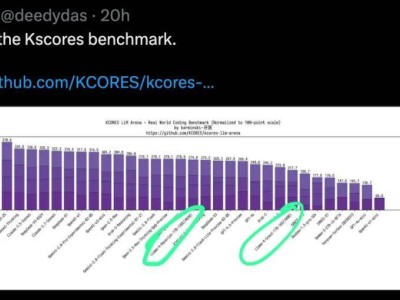
然而,用户的实际体验却大相径庭。许多网友在尝试使用Llama 4进行编程任务时,发现其表现并不如预期。特别是在Kscores基准测试中,专注于代码生成和补全能力的评估,Llama 4 Scout和Maverick的表现明显不如GPT-4o、Gemini Flash等其他模型。
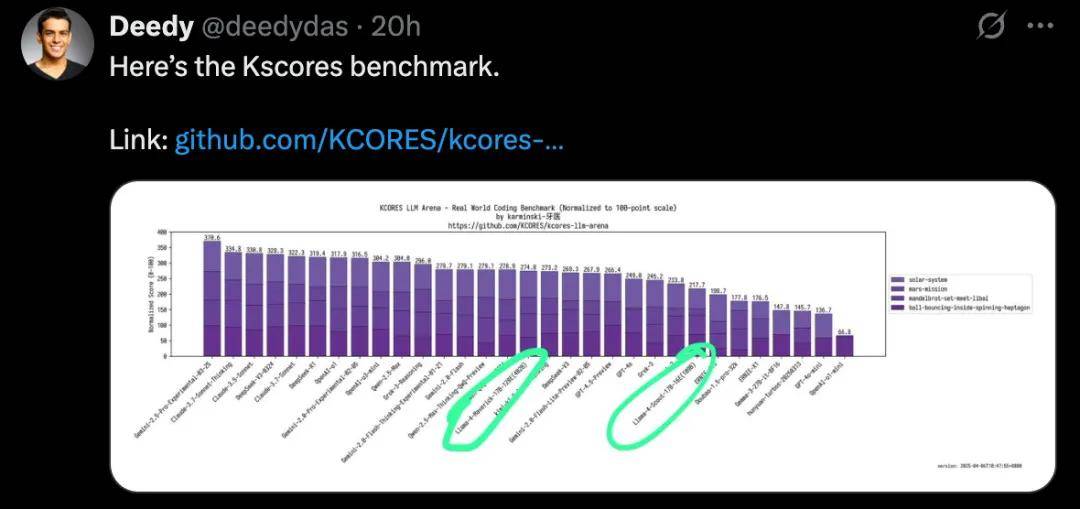
网友@deedydas在社交媒体上发帖,详细对比了Llama 4与其他模型在Kscores测试中的成绩,指出Llama 4在编程相关任务上的不足。这一观点得到了其他用户的广泛共鸣,许多人在评论区表示,无论是Scout还是Maverick,在实际编程场景中的表现都令人失望。

还有网友在Novita AI平台上对Llama 4进行了测试,发现该模型在处理复杂问题时显得力不从心,尽管其响应速度相当快。这一发现进一步加剧了用户对Llama 4实际能力的质疑。
更令人惊讶的是,Google DeepMind的工程师Susan Zhang也对Llama 4在lmsys上的高分表示了质疑。她怀疑meta是否为lmsys定制了一个特定版本的模型,以获取更高的分数。
据科技媒体TechCrunch报道,meta新AI模型的基准测试存在误导性。研究人员发现,公开可下载的Llama 4 Maverick与在LM Arena上托管的版本在行为上存在显著差异。LM Arena上的版本似乎使用了大量表情符号,并给出了冗长的回答,这与用户实际体验到的版本截然不同。

meta在公告中解释称,LM Arena上的Maverick是“实验性聊天版本”,但这一解释并未能平息用户的质疑。许多用户认为,meta为了提高LM Arena上的分数而定制了模型版本,这一行为误导了开发者对模型实际能力的判断。
这一事件再次引发了科技界对AI模型基准测试的争议。尽管基准测试是衡量AI模型性能的重要指标,但如何确保测试的公正性和准确性仍然是一个亟待解决的问题。